
Box64 on RISC-V
The current development cycle of box64 (v0.3.1) has, amongst its objectives, to add Dynarec support for the RISC-V architecture. Using VisionFive2 as my dev. board (thanks StarFive!), I added some infrastructure and split some of the ARM64 Dynarec to create a common ground, and started added some opcode to the newly created Dynarec. I have then be quickly helped by two external contributers on github: ksco and xctan, who since then have pushed hundreds of opcode and helped debugging and finetunned the RISC-V Dynarec!
At this point, the Dynarec is already quite complete (not as much as the ARM64 one, but largely usable), and things are now mostly running on it.
The end result is games are now playable on the VF2, as I have show in a couple of videos already.
CISC vs RISC
But before getting into the details of the Dynarec, let’s start by introducing x86_64 and RISC-V (and ARM64) ISA (Instruction Set Architecture).
x86_64 is the ISA you find on most PC. x86_64 is the 64bits extension of the x86 ISA. While x86 is from Intel, the x86_64 was created by AMD (while Intel was trying to push a new 64bits ISA, not derived from x86, name IA-64, or Itanium, that commercially failed).
x86 and x86_64 are called CISC, for Complex Instruction Set Computer, while RISC-V and ARM are in RISC category, for Reduced Intruction Set Computer.
The idea behind RISC is that the complex opcode, that does a lot of stuff, are also expensive in term of “CPU transistors”, and should not be implemented. Instead, reducing the ISA to a minimum set of instruction will allow the CPU to be simpler and more cost effective, and also generates less heat / consumes less energy because of the decreased complexity. The missing instructions can still be replaced by a sequence of simpler instructions.
Basically, with x86_64, most operations can be done from register to register, or to/from memory and register. This versatility allows writing very compact code. Also, opcodes are of variable length on x86_64. Setting a register to a 64bits value can be done in just 1 opcode. The x86_64 can also access memory in complex scheme, with 2 registers and optionnal multiply 2, 4 or 8, plus a constant offset. It can also be relative to PC (the current address currently executing). And the x86_64 contains hundreds of opcodes, with many extensions (like SSE, AVX), combined with all those access mode. That’s CISC all the way!
On the other hand, RISC-V (and ARM64 in some way), uses the opposite strategy. The opcodes number is very limited. Opcodes are also of fixed size. It’s 32bits per opcode (except for the “C” extension where it’s 16bits per opcode). Loading a 64bits value in a register can take many opcodes, and up to 5 opcodes, or 4 with ARM64). Also, memory operations are separated opcode. Except for the Atomic extension, you cannot do math directly on a memory. You need to load the value from memory to register, do the math, and write back the value, while x86_64 can do that with 1 opcode.
And then, there are the Flags. x86_64, being an ISA with a long history, back to the 8086 days, has some strange flags being computed for each math operations. Some of these flags, like AF or PF, are rarely used and surprisingly complex to emulate. On the other hand, ARM64 has just a minium set of path flags, while RISC-V has no flags at all.
But RISC does have some advantage over x86_64: the number of registers! While x86_64 only have 16 general purpose regs + IP (that is not directly accessible), RISCV (and ARM64) have 32 general purpose register (+ PC that is not directly accessible). But not all are accessible, and some have specific purpose and cannot be used at will. Still, there are more registers available on RISC ISA.
Mapping x86_64 to RISC-V
So, with all that, how box64’s dynarec work?
It’s a simple 1: mapping of the opcodes: for each x86_64 opcode that need to be executed, a sequence of RISC-V opcode will be generated. A sequence of x86_64 opcodes will be a “dynablock”, and it will have an associated sequence of RISC-V opcodes that will do the same logic.
Also, the 32bits -> 64bits on RISC-V is with Sign-extension, while on x86_64 (and ARM64), it’s with Zero-extension. That also add a layer of complexity, while the Dynarec need to ensure that everything is Zero-extended when needed.
All the x86_64 regs are mapped to a specific RISC-V reg, and that 1:1 mapping makes things easier (it is not the case for the other type of registers, like x87 or SSE, but it’s not important for now).
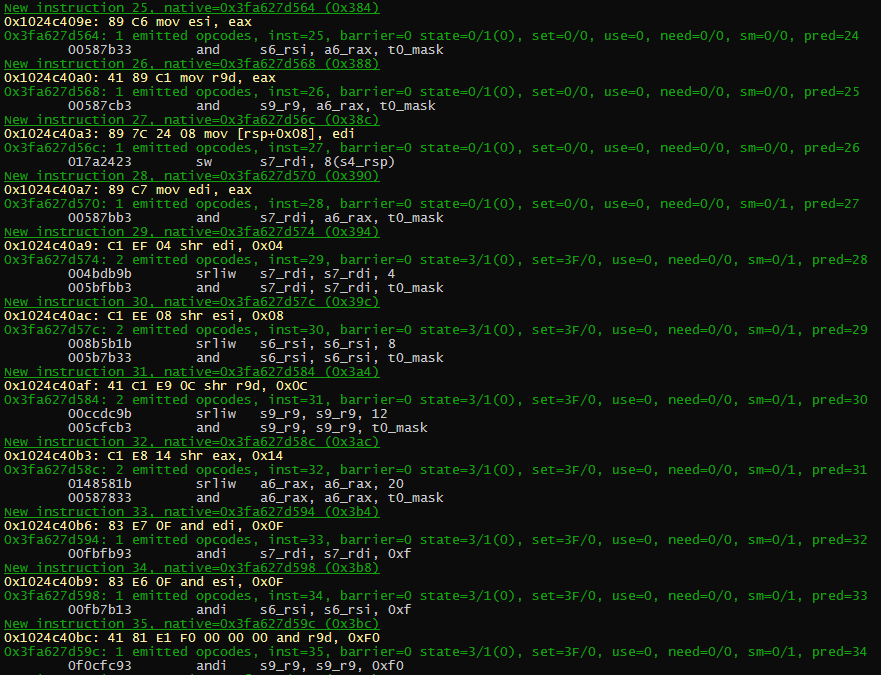
In the picture above, you can see in yellow the x86_64 opcode, and in white the generated RISC-V opcode.
In this particular example, the generated code is very short, and very similar to the original code. This is good, and this is what the dynarec is aiming for, a 1:1 conversion.
You can also notice the green line: that is the status. Because things like Flags are very expensive to compute, the Dynarec tries to not compute flags when it’s not needed. For example, the shr instruction is supposed to compute all those flags. But because in the sequence the falgs are not used (and overwriten by next instruction), the dynarec doesn’t compute the flags, and keeps the code small and fast.
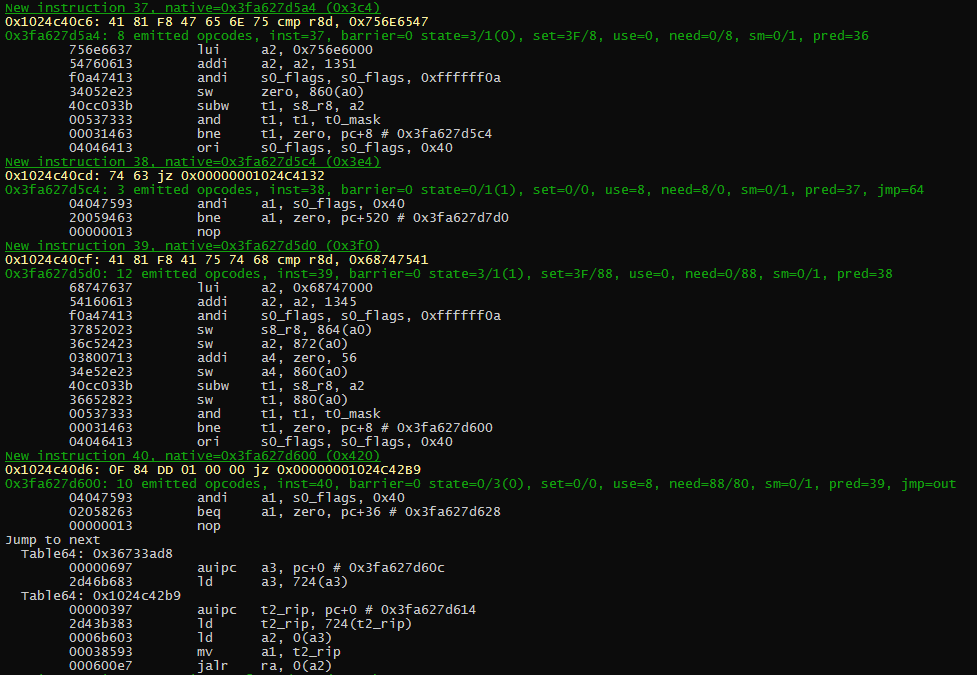
Things change when flags need to be computed. Like on this cmp / jz sequence. Here the 1st cmp needs to compute the ZF flag, that will then be used in the next jz conditional jump. Also in this sequence, you can see that the 1st jz is jumping to an address inside the current dynablock, so the generated code is pretty short, just jumping to the translated address inside the block. The second jz jump out of the dynablock, making the code a bit more complicated as the destination address is not know and needs to be fetched from the “jump table” (I will not explain in details how the jump table works, but if you want to know, ask in the comments and I’ll do another blog entry about that).
All in all, you can imagine that the generated code is quite bigger than the original one. And it is especially true with RISC-V because of the greatly reduced instruction set.
What about the Extensions?
Each ISA has it’s extensions. On x86_64, you have the x87 extension (back in the days, it was a separate co-processor), or SSE/SSE2. Each has it’s own set of registers and opcodes. x87 are focus of floating points Math, with pretty complex function like sin, cos and log/exp. SSE is an SIMD extension (Single Instruction, Multiple Data). It has it’s own set of registers (16 of them on SSE2/x86_64) and a lot of new opcodes. the SIMD can be with integer of different sizes (8/16/32/64 bits) or with Floats and Doubles
While ARM have NEON for the SIMD part, and the VFPU for the Float/Double part (both being merged with ARM64), the RISC-V has the “f” and “d” extensions for the Float and Double part, but not yet an SIMD extension. At least not in the CPU of the VF2.
So, for x87 opcodes, a direct mapping of most of the operations to “f” and “d” extension was possible (most, but not all, because RISC-V ISA doesn’t have operations like Round to Int, so you need a sequence of many operations, including conditionnal jump, to implement that). Also, complex opcodes like sin or exp are always mapped to call the system libm functions, but those are not often used in fact, especially on x86_64. In fact, in x86_64 world, the x87 is not often used, and SSE2 is prefered, as it has most operations available on a single float (named SS for Single Single precision) and single double (named SD for Single Double precision). But RISC-V has no current SIMD extensions (there are, but not widly available), so for SIMD, the Dynarec will use this strategy: for SS and SD opcode, they will be mapped to “f” and “d” extension. For the others opcodes, the SIMD will be emulated with multiple instruction on multiple data (including the PS and PD for Packed Single and Packed Double, so SIMD on float/double). Of course there is some speed penalty, but it’s better than not being able to run things.
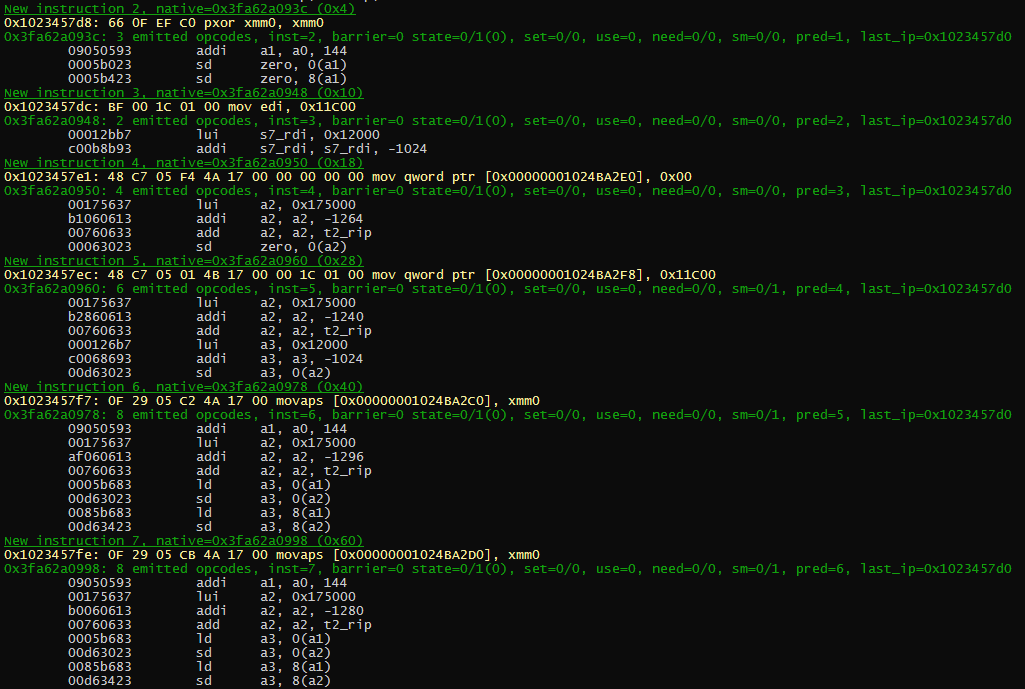
In here you can see the program is using xmm0 to clear 128bits at a time. The generated code is not 100% optimal, but not too bad.
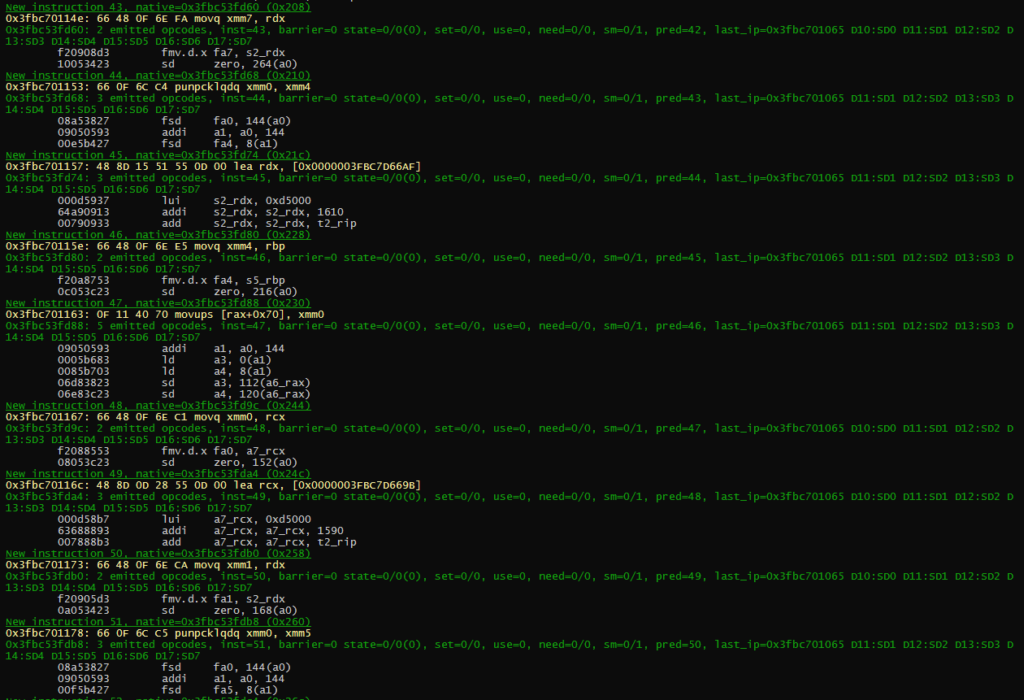
On more complex examples that still use integer, it is still ok in term on generated code.
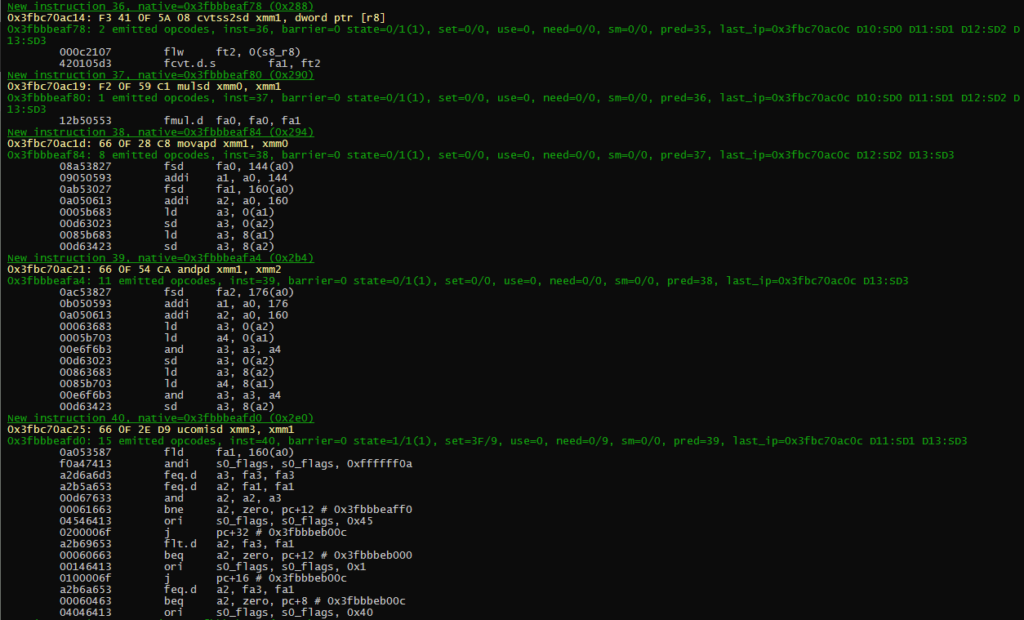
But it can get messy when the code mix SD opcode with PD opcodes. This part can probably be optimized, but that will be for a later release.
RISC-V extensions
RISC-V has many extensions. There are a set of extension that are mandatory to run linux, so the Dynarec will use them without testing for their presense. The VF2 cpu also implement “Zba” and “Zbb” extension, will bring a few handy opcodes. Box64 will detect those extensions and use them if available. The test can be disabled with BOX64_DYNAREC_RV64NOEXT=1 environnement variable. The speed change with or without the extension is not visible most of the time, so that was a bit of a disappointment.
Benchmarks
And now, how all this generated code compares to the original code.
To benchmark dynarec, I use the same opensource program built for x86_64 and for RISC-V, and compare their integrated benchmark value.
I have tested 3 programs: 7-zip v16.02, dav1d v1.0 and openarena v0.8.8
For 7-zip, the procedure is simple, just use 7z b and it will give a number at the end. The higher the number, the better it runs.
| Native | Box64 | Box 64 without extension |
| 4073 | 1027 | 1027 |
| % native | 25 | 25 |
7-zip don’t use SSE/SSE2 extension. It’s mostly general register usage, with conditional jump and very little function call. The 25% of native speed (while ARM64 get more than 50%) is due the many opcodes that need to be emited for each x86_64 opcode.
With dav1d, I used this command line dav1d -i Chimera-AV1-8bit-480x270-552kbps.ivf --muxer null --threads 4 and only tested for 4 threads (the CPU of the VF2 has 4 cores). It gives at the end an “fps” score. The higher the better here too.
| Native | Box64 | Box64 without extension |
| 79.87 | 10.02 | 9.72 |
| % native | 12.5 | 12.2 |
With it’s heavy use of SSE (2, 3 and 4.x) opcode, this test was not supposed to shine. The ARM64 also struggles with this, with around 30% of the native speed. Here it’s less than 50% the speed of ARM, and the lack of SIMD extension can be felt.
For openarena, I used the bench suite borrowed from Phoronix, that I already used a few times on previous benchmarks. For the native RISCV version, I built one using the source port I made a long time ago for the Pandora, adding RISC-V support. It’s here https://github.com/ptitSeb/OpenArenaPandora for those of you that want to build it. I reduced the benchmark video settings, removing Bloom and Refraction, to avoid beeing too much contrained by GPU. At the end, it gives an fps score. The higher the better here too.
| Native | Box64 | Box64 without extension |
| 21.6 | 13.6 | 13.6 |
| % native | 63 | 63 |
Here, you can see box64 “twist” entering into play. It’s not a synthetic benchmark anymore, it’s an actual game. With all the calls to system libs and OpenGL being wrapped and so non-emulated, the final relative speed is much higher. 63% of the native speed is not bad (ARM64 is at 83%). Games can be actually played on the VF2 anyway, so I was expecting good results.
Conclusion
The RISC-V architecture focuses on reducing as much as possible the physical CPU complexity, at the expense of the software side. Box64 generated code can get complex. Still, x86_64 programs can be now run on RISC-V with reasonable speed. Now the focus for Box64/RISC-V will be stability and bug fixing, until the next release.
9 replies on “Box64 and RISC-V”
[…] 详情参考 […]
Have you considered building a super optimizer for this, with the smaller instruction set of risc v it should be practical to brute force the instruction conversion for better performance.
Fun stuff.
Zba and Zbb are not part of the RISC-V application profile and thus should be an opt-in, not an opt-out (or you could probe dynamically). For example, the TH1520 (~ 2X VF2) does not support them.
A few things that should help: do pay attention to scheduling (VF2 in an in-order core), especially of loads; give as much distance to use as possible. Also, propagate the small offset to the memop.
For example, the movaps [0x1024BA2C0], xmm0 translation will be much faster as
ld a3,144(a0)
ld a4,152(a0)
lui a2,0x17500
add a2,a2,t2_rip
sd a3,-1296(a2)
sd a4,-1288(a2)
You should be able to propagate knowledge about how the flags are computed and thus simplify the “jz 0x1024C42B9” example as just
beq t1,zero,…
(why was beq followed by a nop?)
Zbb and Zba are probed, and the opt-out is there in case you still don’t want them (or to do speed comparisin).
The beq is followed by a nop because beq max distance is rather short, and it might be transformed to a bne + b if the jump point is too far. And because this offset is know only on pass 4 (of 4) of the Dynarec, there is a NOP to be sure offset are constants between pass 3 and pass 4.
Also, using the small offset all the way for movaps and co. is planned, but it’s a lot of changes so I lazily postponned that. It will come envetually, as it’s not hard, just a bit painfull to do.
[…] RISCV Boxes […]
Could you possibly spare some time to write a blog detailing how jump table works? As an undergraduate student, I want to express my immense gratitude for your outstanding work on this project. Despite studying the source code, I’ve found it hard to understand the details of jump table and the generated target code related to `jump next` and `table64`. I’d be extremely grateful if you could provide further insight through a blog post. I believe such a post would be of great help to beginners like myself, and others who are trying to understand this. Thank you once again.
Ah ok, I’ll try to think of something.
For SSE equivalent, it seems that people prefer rvv(vector extension) more than packed-SIMD on RISC-V. I have no idea if SSE instructions can be translated into Vector Extension equivalents easily…
Unfortunately Visionfive2 doesn’t support rvv… There are boards with rvv 0.7.1 support now, but I will wait for rvv 1.0 since rvv 0.7.1 is not fully compatible with the latest one