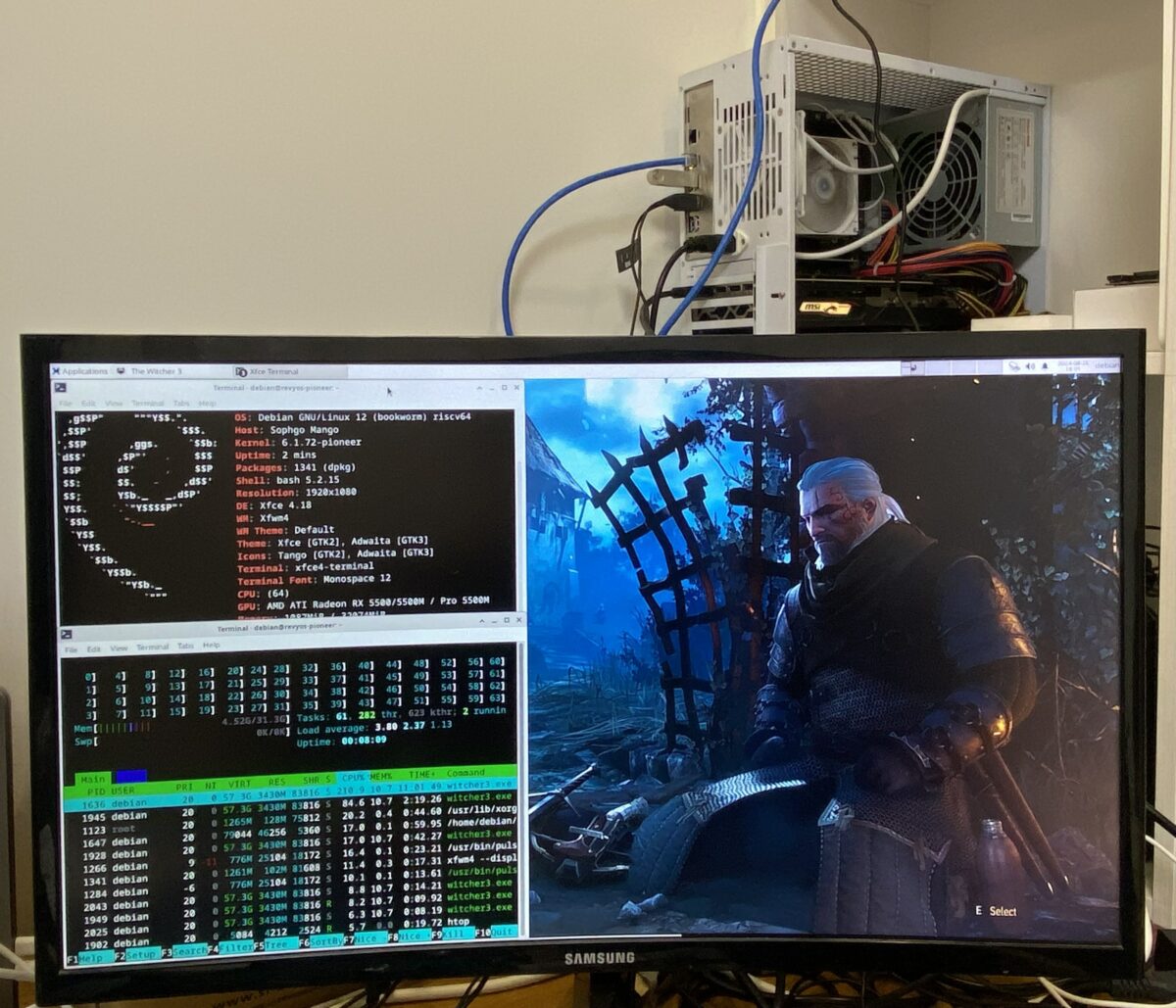
It’s been over a year since our last update on the state of the RISC-V backend, and we recently successfully ran The Witcher 3 on an RISC-V PC, which I believe is the first AAA game ever to run on an RISC-V machine. So I thought this would be a perfect time to write an update, and here it comes.
The Story
A year ago, RV64 DynaRec could only run some relatively “easy-to-run” native Linux games, such as Stardew Valley, World of Goo, etc.
On the one hand, this was because after a large number of new x86_64 instructions were implemented quickly in RISC-V, there were many bugs left in the DynaRec. Things won’t work if you don’t implement the x86_64 ISA correctly. But the most important factor is that we had no RISC-V device could be plugged into an AMD graphics card at the time, and the IMG integrated graphics cards on VisionFive 2 and LicheePi 4A did not support OpenGL, only OpenGL ES.
We can get a certain level of OpenGL support using gl4es, which allows games like Stardew Valley to run, but it is not enough for other more serious Linux games, as well as all Windows games in general.
So this became a hard barrier for us to test more x86 programs in the wider world, until both ptitSeb and I received the Milk-V Pioneer from Sophgo, which is a 64-core RISC-V PC, and of course, it also has a PCIe slot for a graphics card. Many thanks to Sophgo!
In addition, another core contributor xctan also found a way to “plug” an AMD graphics card into VisionFive 2 via the M.2 interface. With that, we were exposed to the wider world and we’ve since fixed a ton of RV64 DynaRec bugs and also added a ton of new x86 instructions. Changing in quantity leads to changes in quality, more and more games were working, and finally, we tried running The Witcher 3 for the first time, and it just worked!
That’s the story of running The Witcher 3 on RISC-V.
What is the Current Status of RISC-V DynaRec?
The x86 instruction set is very very big. According to rough statistics, the ARM64 backend implements more than 1,600 x86 instructions in total, while the RV64 backend implements about 1,000 instructions. Among them, more than 300 of these instructions are newly supported AVX ones that we haven’t implemented at all in RISC-V. Anyway, still need some catching up.
Also, for SSE instructions, we use scalar instructions for implementation, while AArch64 uses the Neon extension and LoongArch64 uses the LSX extension. So the performance is quite poor compared to the other two backends.
However, things are not set in stone. RISC-V has a vector extension called the Vector extension. Yeah I know, so I will call it RVV from now on.
There are already some devices that support RVV on the market, such as the Milk-V Pioneer mentioned above, which supports the xtheadvector extension, which is a variant of RVV version 0.7.1 (things are a bit complicated). In addition, the SpacemiT K1/M1 SoC released not long ago supports the ratified version of RVV 1.0. Currently, the Banana Pi F3 and Milk-V Jupiter equipped with this SoC are already available for purchase.
With these devices available, recently we have added basic RVV support to box64 and implemented several common SSE instructions. However, this work is still very early, so it will not help the performance for now. But the future is promising, right?
Next, let’s talk about the two dark clouds hanging over the RISC-V backend. These are the stuff where I feel RISC-V is most lacking in x86 emulation over the past year.
The Most Wanted Instructions for x86 Emulation
At least in the context of x86 emulation, among all 3 architectures we support, RISC-V is the least expressive one. Compared with AArch64 and LoongArch64, RISC-V lacks many convenient instructions, which means that we have to use more instructions to emulate the same behavior, so the translation efficiency will be lower.
Among them, two instructions are the most critical ones — the ability to pick a range of bits from one register into another; and the ability to insert some bits from one register into a range of another register.
Both LoongArch64 and AArch64 have equivalent instructions, but the RISC-V world has no counterparts for these two instructions, whether official or vendor extensions. It’s not some complex instructions that break the RISC philosophy, so it’s a shame they do not exist on RISC-V.
But why it’s so important for x86 emulation? Because the x86 ISA tends to preserve the unchanged bits.
For example, for an ADD AH, BL instruction, box64 needs to extract the lowest byte from RBX, added to the second lowest byte of RAX, and then insert it back into the second lowest byte of RAX while keeping all other bytes in RAX unchanged.
On LoongArch64, we have BSTRPICK.D to pick the bits, and BSTRINS.D to insert the bits, so the implementation would be:
BSTRPICK.D scratch1, xRAX, 15, 8
BSTRPICK.D scratch2, xRBX, 7, 0
ADD scratch1, scratch1, scratch2
BSTRINS.D xRAX, scratch1, 15, 8Simple and intuitive, right? And it would be as simple on ARM64, with UBFX and BFI opcodes. On RISC-V, however, we have to do this:
# extract the second lowest byte of RAX
SRLI scratch1, xRAX, 8
ANDI scratch1, scratch1, 0xFF
# extract the lowest byte of RBX
ANDI scratch2, xRBX, 0xFF
# do the addition
ADD scratch1, scratch1, scratch2
# fill scratch3 with mask 0xFFFF_FFFF_FFFF_00FF
LUI scratch3, 0xFFFF0
ADDIW scratch3, scratch3, 0xFF
# insert it back
AND xRAX, xRAX, scratch3
ANDI scratch1, scratch1, 0xFF
SLLI scratch1, scratch1, 8
OR xRAX, xRAX, scratch1So a whole of 10 instructions for a simple byte add and this is by no means an isolated case! There are many similar instructions in x86, and their implementation on RISC-V is more cumbersome.
The Frustration of 16-byte Atomic Instructions
x86 has LOCK prefixed instructions for lock-free atomic operations, and box64 mainly uses LR/SC sequence to emulate these. LR/SC is short for Load-Reserved / Store-Conditionally.
For example, for LOCK ADD [RAX], RCX, we generate the following code:
MARKLOCK:
LR.D scratch1, (xRAX)
ADD scratch2, scratch1, xRCX
SC.D scratch3, scratch2, (xRAX)
BNEZ scratch3, MARKLOCKIf the address in RAX is unaligned, things become a bit more complex, but in general, this works really well.
Except for the LOCK CMPXCHG16B instruction, which compares RDX:RAX with 16 bytes of memory and exchanges RCX:RBX to the memory address. While some 16-byte atomic instructions in AArch64 and LoongArch64 can be used to implement this, again, there are no counterparts in RISC-V whatsoever, unfortunately.
Therefore, we cannot implement this instruction as perfectly as other architectures, and even more unfortunately, many programs use this instruction, such as Unity games.
The End
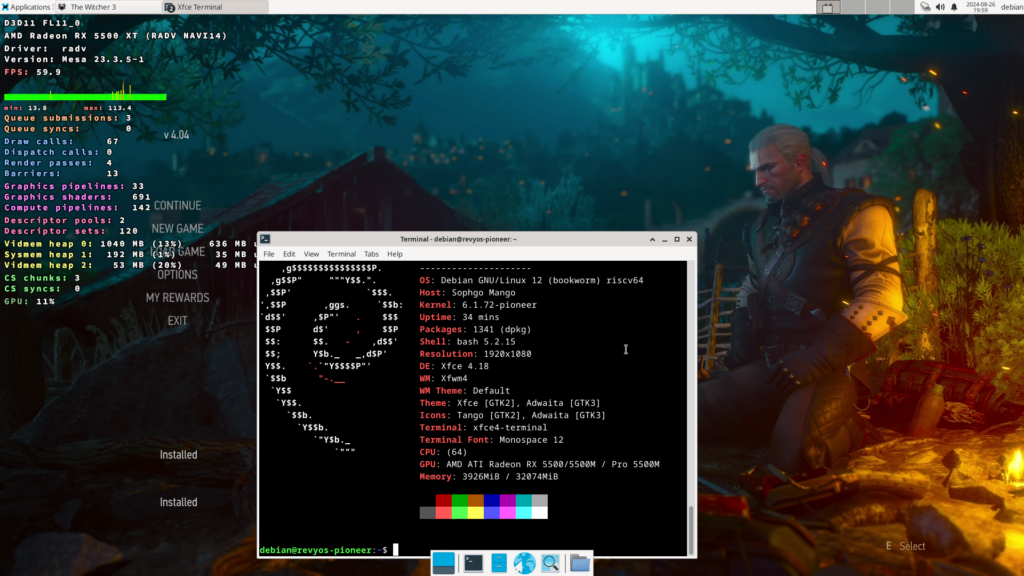
In the end, and despite all those short-comming, The Witcher 3 actually runs, at up to 15 fps in-game and full speed on the main menu with box64! So not that bad for a machine never designed to run AAA games!
11 replies on “Box64 and RISC-V in 2024”
MOV AH, BL can be down shorter with
SLLI scratch1, xRBX, 8
XOR scratch1, xRAX // get bits that are different between xRAX and xRBX<<8
LI scratch2, 0xff
SLLI scratch2, scratch2, 8
AND scratch1, scratch2 // mask the difference to just byte 1
XOR xRAX, scratch1 // toggle all bits that are different
You can do the x86 `add ah, bl` in RISC-V in 7 opcodes:
LUI scratch2, 0xFFFF0
SLLI scratch1, xRBX, 8
ADD scratch1, xRAX
AND xRAX, xRAX, scratch2
NOT scratch2, scratch2
AND scratch1, scratch1, scratch2
OR xRAX, xRAX, scratch1
But it’s hard to write a JIT recompiler to do this without hand-coding each one of those special cases
I wonder if you could improve performance by dropping Wine and DXVK from the chain. Witcher 3 has a native Linux version, after all.
I re-checked. On GOG, there is only the Windows version of the Witcher 3. But there is a linux version of the Witcher 2, but that’s an older game.
And the ‘native’ version of Witcher 2 is not native. It uses the eON compatibility layer, which is some proprietary wine-like. It’s not very good.
The milk-v jupiter has the ‘B’ extension for bit manipulation. That may be what you need?
Apperently you need the B extension indeed, which is a combination of several bit manipulation extensions. It should be in the RVA23 profile and future risc-v processors should have it.
# Extract the second lowest byte of RAX
bexti scratch1, xRAX, 8, 8 # Extract 8 bits starting from bit 8
# Extract the lowest byte of RBX
bexti scratch2, xRBX, 0, 8 # Extract 8 bits from position 0
# Add the two bytes
add scratch1, scratch1, scratch2
# Insert the result back into RAX at position 8
bdep xRAX, scratch1, 0xFF00 # Insert 8 bits into bits 8–15
Is there a reason for not using amoadd?
amoadd can only be used when x86 flags are not needed for the opcode. So it’s easily doable but needs some more if in code: it will probably be done later but that’s not a priority for now.
amo operations write the previous value to rd:
amoadd.d.aqrl scratch1, xRCX, (xRAX)
add scratch2, scratch1, xRCX
should do the trick? I’m bikeshedding a bit here, LR/SC is fine, and until Zacas hits hardware there’s a bigger performance limiter
We have replaced LR/SC with AMO* instructions when possible, thanks for bringing this up!
PR: https://github.com/ptitSeb/box64/pull/2028