Hello everyone! A month and a half ago, we wrote about the latest status of the RISC-V DynaRec (Dynamic Recompiler, which is the JIT backend of Box64) and shared the gratifying progress of running The Witcher 3 on RISC-V. If you haven’t seen that post yet, don’t miss it! Anyway, last month, we were not just sitting there and twiddling our thumbs either, but focused on performance improvement and now we have something to share.
Are We SIMD Yet?
The x86 instruction set has slowly expanded a huge number of SIMD instructions over the years, scattered across multiple SIMD extensions, from the original MMX to SSE, SSE2, SSE3, SSSE3, SSE4, to AVX, AVX-2, AVX-512 as well as the upcoming AVX10. You can probably guess that these instructions must have vast applications to be worth such an explosion to the encoding space.
In fact, almost all x86 programs nowadays will more or less use SIMD instructions, thanks to modern compilers. In particular, some performance-sensitive and parallel-friendly programs will utilize hand-written SIMD kernels in hot code paths to have a massive boost in performance. Therefore, box64 needs to translate these instructions efficiently.
Fortunately, x86 is not the only instruction set with SIMD or vector extensions. It is so important that almost all instruction sets have it. For example, AArch64 has Neon, SVE, and SVE2, LoongArch has LSX and LASX, and RISC-V has the Vector extensions (or RVV). Essentially, the goal of these extensions is the same, which is to speed up the execution of parallel-friendly code. Therefore, even though they have differences in this way or that, they are generally similar, and many basic instructions are completely identical, and thus can be translated one-to-one by emulators like box64.
So how well does box64 support these x86 SIMD instructions? Well, this is a complicated question. For example, the most complete AArch64 DynaRec currently supports almost all instructions from MMX to AVX-2. In simple terms, these instructions will be translated into one or more Neon instructions to do the equivalent work. Meanwhile, the least complete LoongArch64 DynaRec currently only supports a small subset of MMX and SSE* instructions and unimplemented opcodes will fall back to the interpreter, which is very slow.
So, what about our beloved RISC-V? Are we SIMD yet?
Well, a month and a half ago, the answer was no. RISC-V DynaRec did implement most instructions from MMX to SSE4, but these instructions are emulated with scalar instructions.
For example, for the SSE2 paddq opcode, what this instruction does is:
DEST[63:0] := DEST[63:0] + SRC[63:0];
DEST[127:64] := DEST[127:64] + SRC[127:64];So how is it emulated on RISC-V? Let’s take a look at it via the dump functionality of Box64:
0x10000b858: 66 0F D4 C1 paddq xmm0, xmm1
0x40012c6d24: 8 emitted opcodes, inst=8, ...
09053683 LD a3, a0, 0x90(144)
0a053703 LD a4, a0, 0xa0(160)
00e686b3 ADD a3, a3, a4
08d53823 SD a3, a0, 0x90(144)
09853683 LD a3, a0, 0x98(152)
0a853703 LD a4, a0, 0xa8(168)
00e686b3 ADD a3, a3, a4
08d53c23 SD a3, a0, 0x98(152)You can see that the translation is implemented by two LOAD LOAD ADD STORE sequences, totaling 8 instructions. This is probably the easiest opcode to simulate so it will be even worse for other more complex opcodes.
So how is this implemented on AArch64?
0x10000b858: 66 0F D4 C1 paddq xmm0, xmm1
0xffffb7ff1848: 1 emitted opcodes, inst=8, ...
4ee18400 VADD V0.2D, V0.2D, V1.2DAh ha, this opcode is translated one-to-one to the VADD instruction! No surprises at all.
As you can imagine, this approach on RISC-V will indeed have much better performance than simply falling back to the interpreter, but it is far inferior compared to AArch64 with Neon instructions at hand.
The RISC-V instruction set is known for its diversity (you could also say fragmentation if you hate RISC-V). This means that in addition to the basic instruction set, vendors have full freedom to implement or not implement official extensions, and to add or not add custom extensions.
You see, in AArch64, the Neon extension is mandatory, so box64 can use it at will, no need to worry about its presence. But RVV is very different. For example, the JH7110 (VisionFive 2, MilkV Mars, etc.) does not have any vector extensions, while the SpacemiT K1/M1 (Banana Pi F3, MilkV Jupiter, etc.) supports RVV 1.0 with a vector register width of 256 bits, and SG2042 (MilkV Pioneer) supports the old RVV version 0.7.1 (or XTheadVector) with a register width of 128 bits.
In fact, the one on SG2042 is not strictly 0.7.1, but based on 0.7.1, that why it is called XTheadVector. Although it has some differences with RVV 1.0, such as the encoding of instructions, the behavior of some instructions, and the lack of a small number of instructions, it is generally very similar.
Anyway, on RISC-V we cannot assume that RVV (or XTheadVector) is always present, so using a scalar implementation as a fallback is reasonable and necessary.
But for a long time, the RISC-V DynaRec only had a scalar solution, which was a huge waste of hardware performance for hardware with RVV (or XTheadVector) support, until recently. Yes, in the past month, we added preliminary RVV and XTheadVector support to the RISC-V backend! Also, we managed to share most of the code between RVV 1.0 and XTheadVector, so no additional maintenance burden for supporting 2 extensions at once.
Ohhhh, I can’t wait, let me show you what that paddq looks like now!
0x10000b858: 66 0F D4 C1 paddq xmm0, xmm1
0x40012c64d4: 3 emitted opcodes, inst=8, ...
c1817057 VSETIVLI zero, 2, e64, m1, tu, mu
02b50557 VADD.VV v10, v11, v10, noneHmmm, okay, it looks much nicer. But, you may ask, what the heck is that VSETIVLI? Well… that’s a long story.
In “traditional” SIMD extensions, the width of the selected elements is encoded directly into the instruction itself, e.g. in x86 there is not only paddq for 64bit addition, but also paddb, paddw and paddd for 8bit, 16bit and 32bit respectively.
In RVV, on the other hand, there is only 1 vector-wise addition instruction, which is vadd.vv. The selected element width (SEW) is instead stored in a control register called vtype, and you need to use the dedicated vsetivli instruction to set the value of vtype. Every time a vector instruction is executed, the vtype register must be in a valid state.
In the above vsetivli instruction, we essentially set the SEW to 64bit along with other configurations. However, inserting a vsetivli before every SIMD opcode doesn’t sound like a good idea. If vtype does not need to change between adjacent opcodes, we can safely eliminate them. And that’s how we did it in Box64.
Look at these dumps:
0x3f0000586c: 66 0F 70 C8 F5 pshufd xmm1, xmm0, 0xF5
0x70ce184b3520: 9 emitted opcodes, inst=117, ...
00030737 LUI a4, 0x30(48)
0037071b ADDIW a4, a4, 0x3(3)
01071713 SLLI a4, a4, 0x10(16)
00170713 ADDI a4, a4, 0x1(1)
01071713 SLLI a4, a4, 0x10(16)
00170713 ADDI a4, a4, 0x1(1)
5e0741d7 VMV.V.X v3, a4
c1027057 VSETIVLI zero, 4, e32, m1, tu, mu
3aa185d7 VRGATHEREI16.VV v11, v10, v3, none
0x3f00005871: 66 0F FE C3 paddd xmm0, xmm3
0x70ce184b3544: 3 emitted opcodes, inst=118, ...
0c050593 ADDI a1, a0, 0xc0(192)
0205e687 VLE32.V v13, a1, none, 1
02d50557 VADD.VV v10, v13, v10, none
0x3f00005875: 66 0F FE C1 paddd xmm0, xmm1
0x70ce184b3550: 1 emitted opcodes, inst=119, ...
02b50557 VADD.VV v10, v11, v10, none
0x3f00005879: 66 0F 72 E0 0E psrad xmm0, 0x0E
0x70ce184b3554: 1 emitted opcodes, inst=120, ...
a6a73557 VSRA.VI v10, v10, 0xe(14), none
0x3f0000587e: 66 0F 38 1E C8 pabsd xmm1, xmm0
0x70ce184b3558: 3 emitted opcodes, inst=121, ...
a6afb1d7 VSRA.VI v3, v10, 0xffffffff(-1), none
2e3505d7 VXOR.VV v11, v3, v10, none
0ab185d7 VSUB.VV v11, v11, v3, noneYou can see that among the 5 SSE opcodes, as the actual SEW has not changed, we only call vsetivli once at the top. We achieved this by adding a SEW tracking mechanism to the DynaRec and only inserting vsetvli when it’s necessary. This tracking not only includes the linear part but also considers control flow. A lot of state caching in box64 is done using a similar mechanism, so nothing new here.
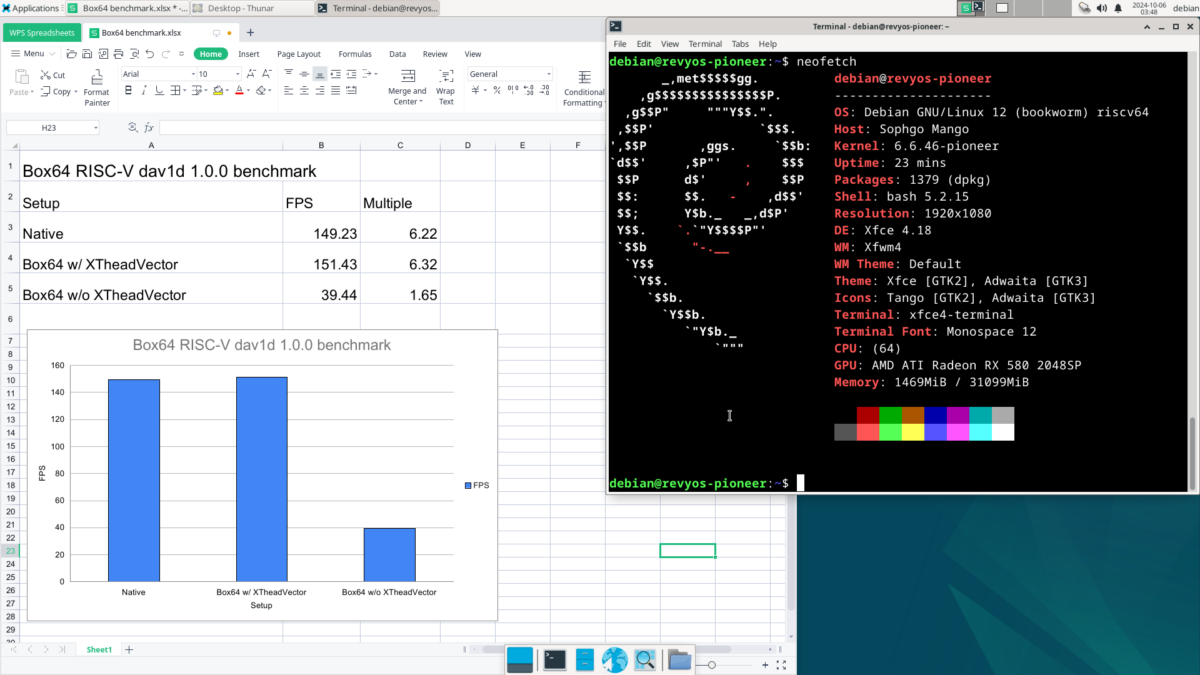
For now, we haven’t implemented every x86 SIMD instruction in RVV / XTheadVector, but we implemented enough of them to do a proper benchmark. By tradition, we use the dav1d AV1 decoding benchmark as a reference, which happens to use SSE instructions a LOT, and here is the command we used:
dav1d -i ./Chimera-AV1-8bit-480x270-552kbps.ivf --muxer null --threads 8We did the test on the MilkV Pioneer, which has the XTheadVector extension.
We also tested RVV 1.0 with the SpacemiT K1, the result is more or less the same.
### Native
dav1d 1.0.0 - by VideoLAN
Decoded 8929/8929 frames (100.0%) - 149.23/23.98 fps (6.22x)
### Box64 w/ XTheadVector
dav1d 1.0.0 - by VideoLAN
Decoded 8929/8929 frames (100.0%) - 151.43/23.98 fps (6.32x)
### Box64 w/o XTheadVector
dav1d 1.0.0 - by VideoLAN
Decoded 8929/8929 frames (100.0%) - 39.44/23.98 fps (1.65x)Compared to the scalar version, we get a nearly 4x performance improvement! Even faster than native! Ugh… well, the faster-than-native part is more symbolic. The comparison is meaningful only if native dav1d fully supports XTheadVector, which the native dav1d does not support at all.
Last But Not Least
In the last post, we complained about RISC-V not having bit range insert and extract instructions, and therefore not being able to efficiently implement things like 8bit and 16bit x86 opcodes. camel-cdr came up with a great solution: https://news.ycombinator.com/item?id=41364904. Basically, for an ADD AH, BL, you can implement it using the following 4 instructions!
# a0 = rax, a1 = rbx
slli t0, a1, 64-8
rori a0, a0, 16
add a0, a0, t0
rori a0, a0, 64-16The core idea is to shift the actual addition to the high part to eliminate the effect of the carry, which is a pretty neat trick. And it can be applied to almost all of the 8-bit and 16-bit opcodes when there is no eflags computation required, which covers most scenarios. We have adopted this approach as a fast path to box64. Thank you very much camel-cdr!
This method requires an instruction from the Zbb extension called RORI (Rotate Right Immediate). Fortunately, at least all the RISC-V hardware I own provides this extension, so it’s commonly available. (Well, SG2042 does not have Zbb, but it has an equivalent instruction TH.SRRI in the XTheadBb extension).
We also found that in the XTheadBb extension, there is a TH.EXTU instruction, which did the bit extract operation. We’ve adapted this instruction to some places too, for example, the indirect jump table lookup — when box64 DynaRec needs to jump out of the current dynablock to the next dynablock, it needs to find where the next is.
In short, there are two cases. The first is a direct jump, that is, the jump address is known at compile time. In this case, box64 can directly query the jump table at compile time to obtain the jump address and place it in the built-in data area of dynablock, which can be used directly when jumping at runtime, no problem there.
The second is an indirect jump, that is, the jump address is stored in a register or memory and is unknown at compile time. In this case, box64 has no choice but to generate code that queries the jump table at runtime.
The lookup table is a data structure similar to page table, and the code for the lookup is as follows:
Jump to next
00080393 ADDI t2_rip, a6_rax, 0x0(0)
00001697 AUIPC a3, 0x1(1)
c146b683 LD a3, a3, 0xfffffc14(-1004)
02e3d613 SRLI a2, t2_rip, 0x2e(46)
00361613 SLLI a2, a2, 0x3(3)
00c686b3 ADD a3, a3, a2
0006b683 LD a3, a3, 0x0(0)
00200737 LUI a4, 0x200(512)
ff87071b ADDIW a4, a4, 0xfffffff8(-8)
0193d613 SRLI a2, t2_rip, 0x19(25)
00e67633 AND a2, a2, a4
00c686b3 ADD a3, a3, a2
0006b683 LD a3, a3, 0x0(0)
0073d613 SRLI a2, t2_rip, 0x7(7)
00e67633 AND a2, a2, a4
00c686b3 ADD a3, a3, a2
0006b683 LD a3, a3, 0x0(0)
3ff3f613 ANDI a2, t2_rip, 0x3ff(1023)
00361613 SLLI a2, a2, 0x3(3)
00c686b3 ADD a3, a3, a2
0006b603 LD a2, a3, 0x0(0)
00038593 ADDI a1, t2_rip, 0x0(0)
000600e7 JALR ra, a2, 0x0(0)Hmmm, I know, it’s hard to see what’s happening there, but it seems like a lot of instructions there for a jump, right? But with TH.ADDSL and TH.EXTU from XTheadBb, it becomes:
Jump to next
00080393 ADDI t2_rip, a6_rax, 0x0(0)
00001697 AUIPC a3, 0x1(1)
bf46b683 LD a3, a3, 0xfffffbf4(-1036)
fee3b60b TH.EXTU a2, t2_rip, 0x3f(63), 0x2e(46)
06c6968b TH.ADDSL a3, a3, a2, 0x3(3)
0006b683 LD a3, a3, 0x0(0)
b5c3b60b TH.EXTU a2, t2_rip, 0x2d(45), 0x1c(28)
06c6968b TH.ADDSL a3, a3, a2, 0x3(3)
0006b683 LD a3, a3, 0x0(0)
6ca3b60b TH.EXTU a2, t2_rip, 0x1b(27), 0xa(10)
06c6968b TH.ADDSL a3, a3, a2, 0x3(3)
0006b683 LD a3, a3, 0x0(0)
2403b60b TH.EXTU a2, t2_rip, 0x9(9), 0x0(0)
06c6968b TH.ADDSL a3, a3, a2, 0x3(3)
0006b603 LD a2, a3, 0x0(0)
00038593 ADDI a1, t2_rip, 0x0(0)
000600e7 JALR ra, a2, 0x0(0)Now it’s much more readable; you should be able to see that this is a 4-layer lookup table, and the number of instructions required has also been reduced a bit.
Okay, all these optimizations look good, but does it show effects in real-world benchmarks? Well, we tested 7z b, dav1d and coremark, and there are no visible differences in the scores with or without XTheadBb. But, a quote from the SQLite website:
A microoptimization is a change to the code that results in a very small performance increase. Typical micro-optimizations reduce the number of CPU cycles by 0.1% or 0.05% or even less. Such improvements are impossible to measure with real-world timings. But hundreds or thousands of microoptimizations add up, resulting in measurable real-world performance gains.
So, let’s do our best and hope for the best!
In the End
Well, this is the end of this post, but it is not the end of optimizing the RISC-V DynaRec, we’ve barely started!
Next, we’ll add more SSE opcodes to the vector units, as well as MMX opcodes and AVX opcodes, and we will make the RISC-V DynaRec as shiny as the AArch64 one!
So, a bit more work, and we can have a look again at gaming, with, hopefully, playable framerates and more games running so stay tuned!
3 replies on “Optimizing the RISC-V Backend”
Great stuff!
Did this work result in any noticeable performance improvement regarding Witcher 3 emulation?
Well, not yet, probably because not enough opcodes have been implemented in RVV unit yet.
After implementing dozens of new SSE* opcodes in RVV and XTheadVector, I tested Witcher 3 again and here are the results.
BIGBLOCK=3 CALLRET=1 RV64NOEXT=0
20fps
BIGBLOCK=1 CALLRET=0 RV64NOEXT=0
14fps
BIGBLOCK=3 CALLRET=1 RV64NOEXT=vector
14fps
BIGBLOCK=1 CALLRET=0 RV64NOEXT=vector
13fps
1. Exactly the same scene, character not moving, waiting for fps to stabilize before recording
2. BIGBLOCK=3 and CALLRET=1 are some common options to get more performance
3. RV64NOEXT=vector will disable vector unit
As you can see, performance is indeed improved!